Large-Scale Prediction of Collision Cross-Section Values for Metabolites in Ion Mobility-Mass Spectrometry
Abstract
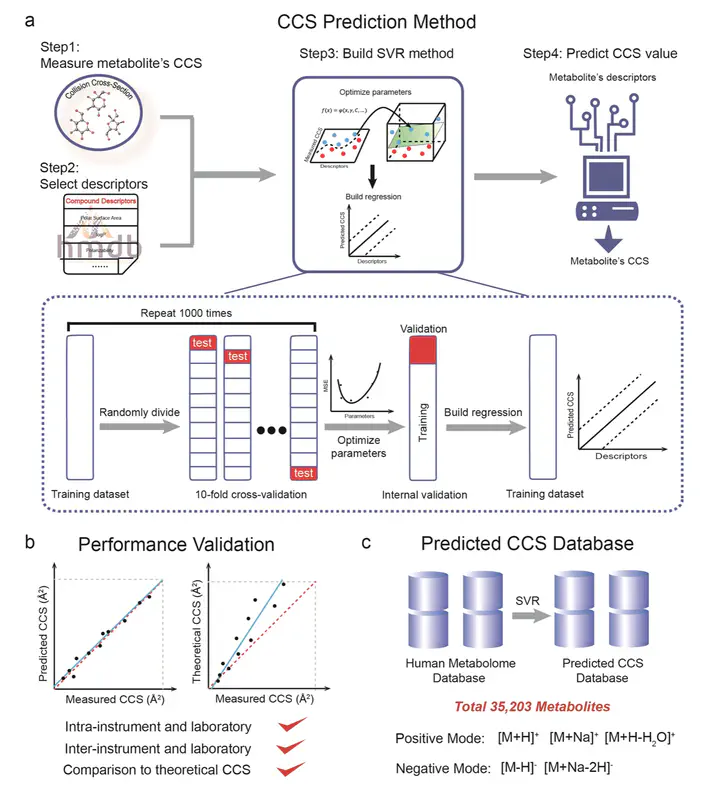
The rapid development of metabolomics has significantly advanced health and disease related research. However, metabolite identification remains a major analytical challenge for untargeted metabolomics. While the use of collision cross-section (CCS) values obtained in ion mobility-mass spectrometry (IM-MS) effectively increases identification confidence of metabolites, it is restricted by the limited number of available CCS values for metabolites. Here, we demonstrated the use of a machine-learning algorithm called support vector regression (SVR) to develop a prediction method that utilized 14 common molecular descriptors to predict CCS values for metabolites. In this work, we first experimentally measured CCS values (ΩN₂) of ∼400 metabolites in nitrogen buffer gas and used these values as training data to optimize the prediction method. The high prediction precision of this method was externally validated using an independent set of metabolites with a median relative error (MRE) of ∼3%, better than conventional theoretical calculation. Using the SVR based prediction method, a large-scale predicted CCS database was generated for 35 203 metabolites in the Human Metabolome Database (HMDB). For each metabolite, five different ion adducts in positive and negative modes were predicted, accounting for 176 015 CCS values in total. Finally, improved metabolite identification accuracy was demonstrated using real biological samples. Conclusively, our results proved that the SVR based prediction method can accurately predict nitrogen CCS values (ΩN₂) of metabolites from molecular descriptors and effectively improve …
Xiaotao SHEN
Nanyang Assistant Professor
Metabolomics, Multi-omics, Bioinformatics, Systems Biology.